

Unsere IT Recruitment Dienstleistungen für Unternehmen
Link to: FullService IT Recruitment Paket

FullService IT Recruitment Paket
IT-Spezialisten sind schwer zu finden?
Wir übernehmen den gesamten Rekrutierungsprozess.
Link to: IT Active Sourcing Paket
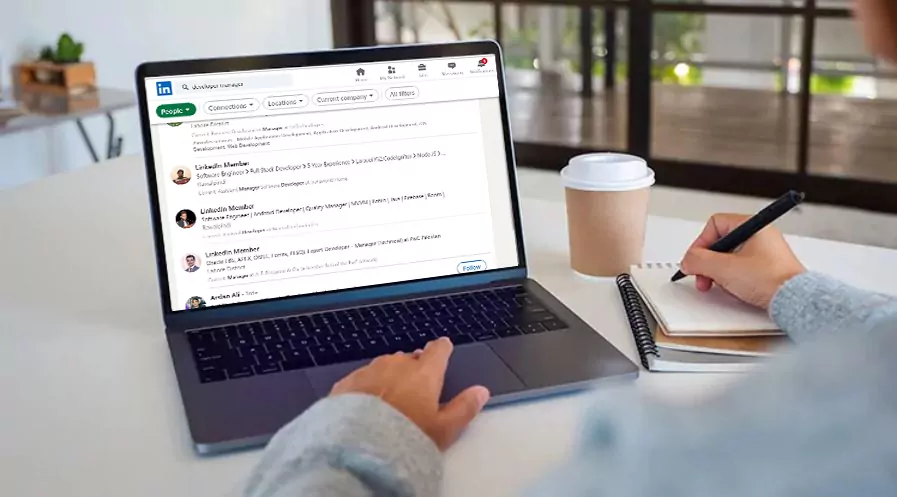
IT Active Sourcing Paket
Erhalten Sie Lebensläufe von Bewerbern für Ihre IT-Stellen zu einem günstigen Festpreis.
Link to: IT Recruitment Process Outsourcing

Internationale IT Experten
Haben Sie schon einmal darüber nachgedacht, IT-Spezialisten einzusetzen, anstatt sie einzustellen?
Es ist an der Zeit, dies zu tun.

Wir sind spezialisiert auf die Vermittlung von
IT-Fachkräften
Wir nutzen unsere 25-jährige Erfahrung in der IT-Branche, um Arbeitgebern dabei zu unterstützen, die besten
IT-Talente zu finden. Wählen Sie aus unseren IT-Recruitment-Dienstleistungen je nach Ihren Prioritäten und Ihrem Budget. Wir vermitteln auch internationale IT-Experten für Ihre schwer zu besetzenden IT-Stellen.

0
Jahre Erfahrung
0+
Länder aus denen unsere
Mitarbeiter arbeiten


IT-Personaldienstleister, der schnelle Unterstützung leistet
Selbstrekrutieren funktioniert möglicherweise nicht für alle, aber das bedeutet nicht, dass Sie aufgeben sollten.
Ihre Zeit ist kostbar. Deshalb unterstützen wir Sie bei Ihrer Mitarbeitersuche und dem kompletten Einstellungsprozess.

